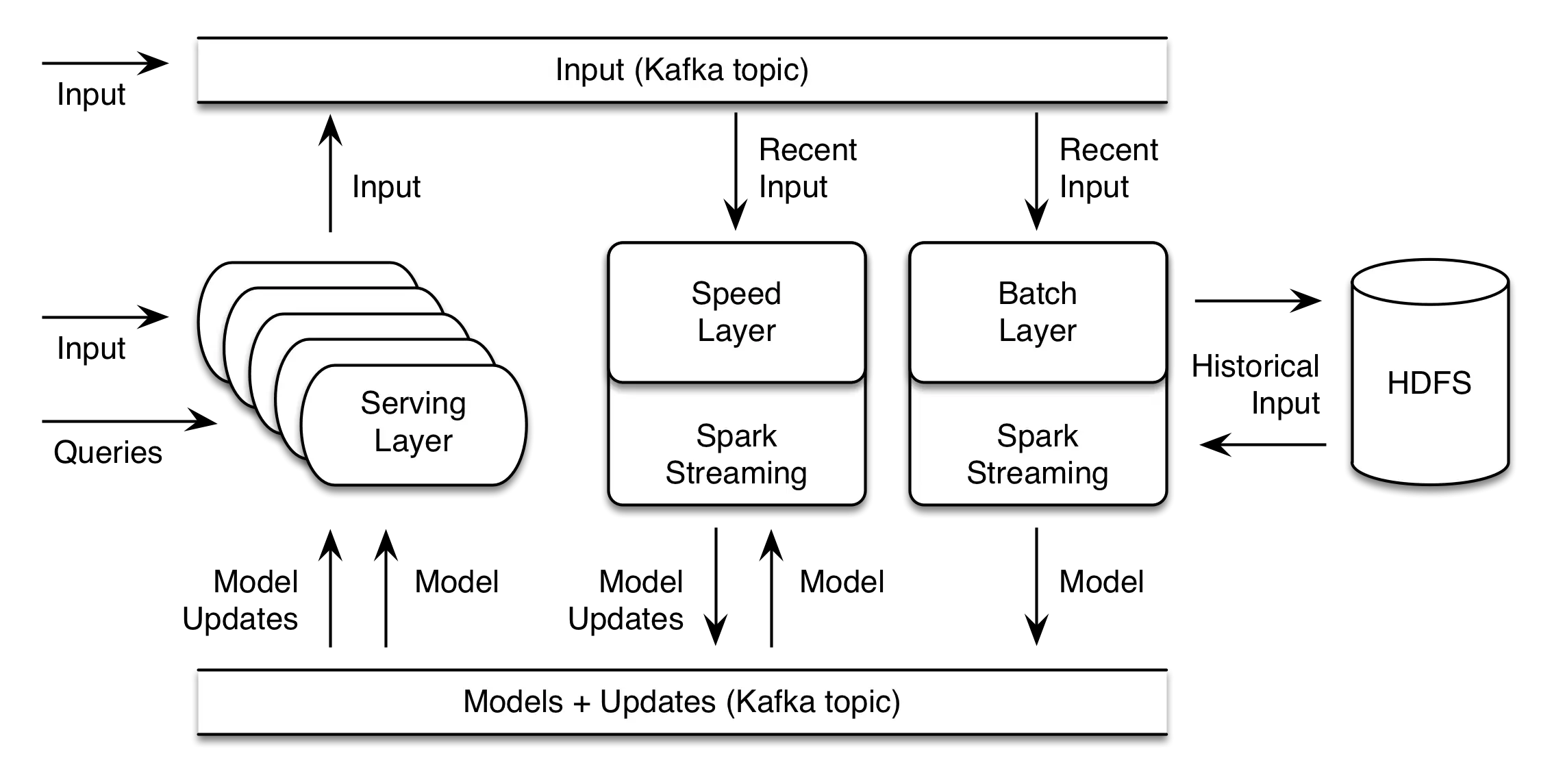
You Might Like
-

Data Analytics and Visualization Illustration -
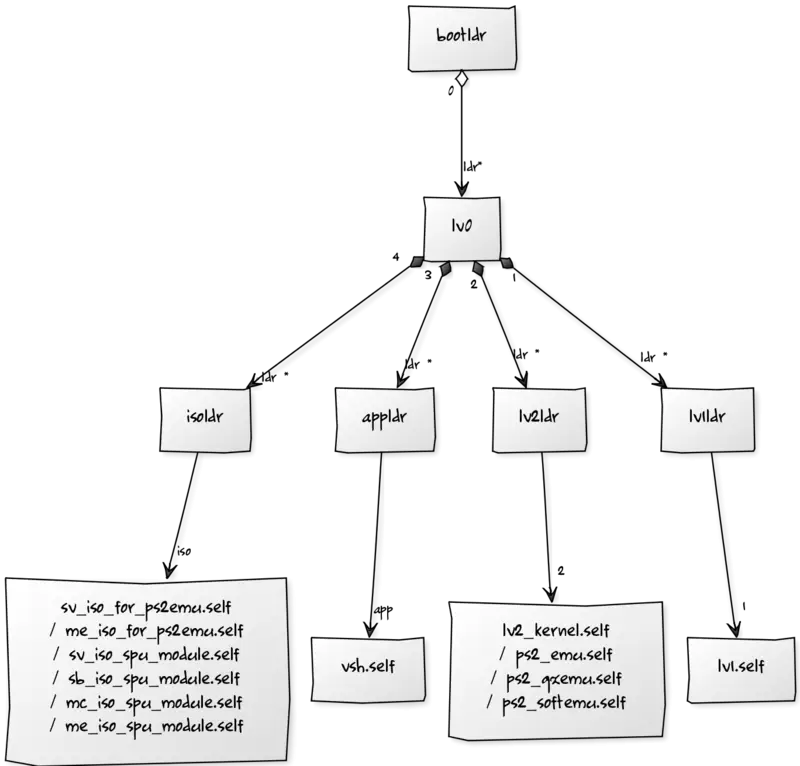
Flowchart Illustration Diagram for Process Representation -

Isometric Data Network Illustration with Technology Elements -
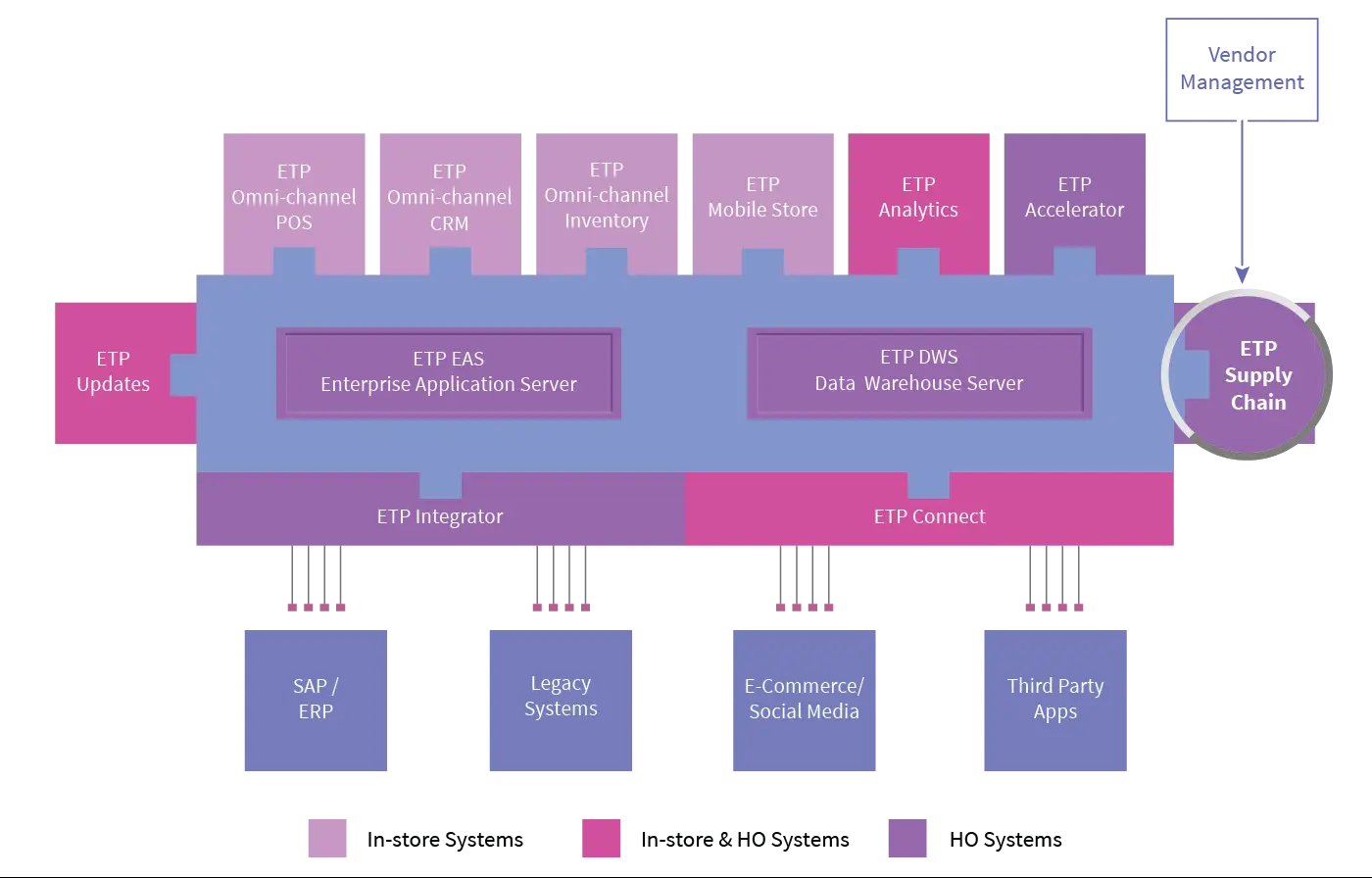
ETP Supply Chain Management Diagram -
Network Connection Diagram Representing Technology Flow -

Apache Spark Logo for Big Data Application -

Gears and Computer Technology Illustration -

Cloud Computing and Data Management -
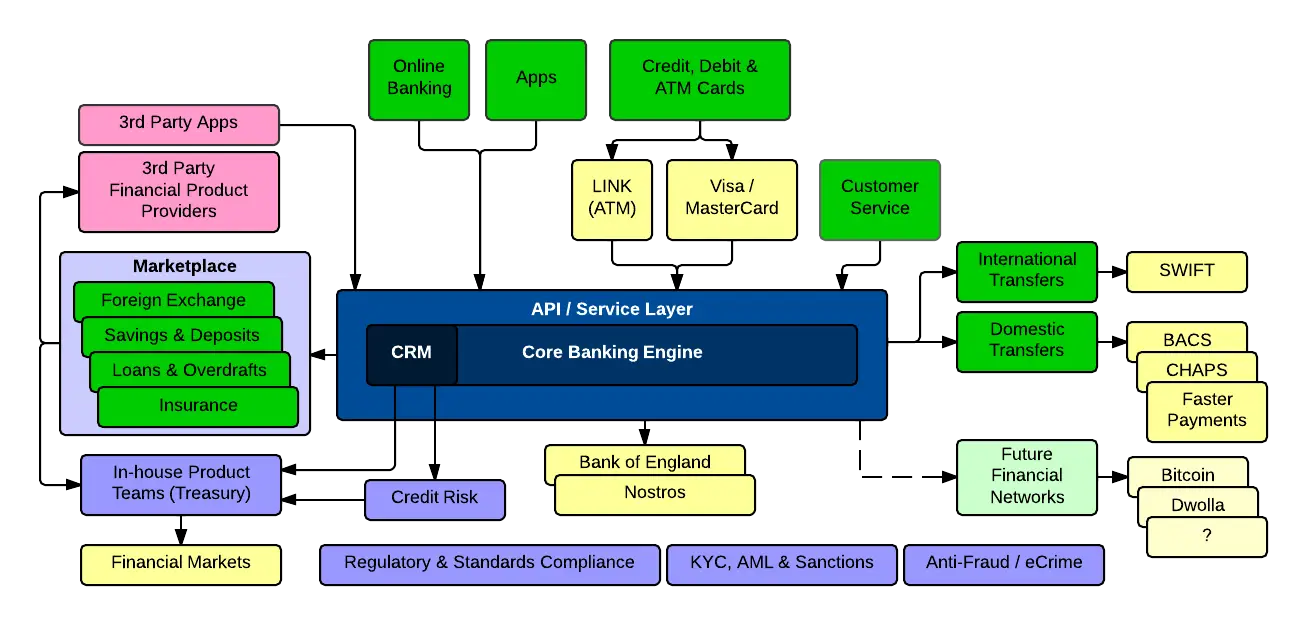
Comprehensive Banking System Diagram